| curl_init | Inicjuje sesję i zwraca uchwyt dla reszty funkcji. Przybiera jeden opcjonalny argument tj. adres URL, adres można zamiast tutaj podać w opcji “CURLOPT_URL”. | $ch = curl_init('https://tosiek.pl/'); |
$ch = curl_init('https://tosiek.pl/'); |
| curl_setopt | Ustawia pojedynczą opcję dla zwykłej sesji cURL. | curl_setopt($ch, CURLOPT_URL, "https://tosiek.pl/"); |
curl_setopt($ch, CURLOPT_URL, "https://tosiek.pl/"); |
| curl_setopt_array | Ustawia kilka opcji dla sesji curla na raz przy pomocy tablicy gdzie klucz to opcja a wartość to ustawienie dla tej opcji. | $options = array(
CURLOPT_URL => 'https://tosiek.pl/',
CURLOPT_HEADER => false,
);
curl_setopt_array($ch, $options); |
$options = array( CURLOPT_URL => 'https://tosiek.pl/', CURLOPT_HEADER => false,);curl_setopt_array($ch, $options); |
| curl_exec | Wywołuje sesję curl_init z podanymi wcześniej parametrami, zwraca TRUE przy powodzeniu i FALSE przy nieudanym wywołaniu. Jeśli “CURLOPT_RETURNTRANSFER” zostanie ustawione na TRUE to ta funkcja zwróci zawartość strony przy udanym wywołaniu lub FALSE przy nieudanym. | $result = curl_exec($ch); |
$result = curl_exec($ch); |
| curl_getinfo | Pobiera informacje o wykonanej sesji cURL i zwraca je w postaci tablicy. | $curl_info = curl_getinfo($ch);
$curl_info = array(
'url' => 'https://tosiek.pl/',
'content_type' => 'text/html; charset=utf-8',
'http_code' => 200,
'header_size' => 862,
'request_size' => 52,
'filetime' => -1,
'ssl_verify_result' => 0,
'redirect_count' => 0,
'total_time' => 0.344,
'namelookup_time' => 0.047,
'connect_time' => 0.172,
'pretransfer_time' => 0.172,
'size_upload' => 0,
'size_download' => 80,
'speed_download' => 232,
'speed_upload' => 0,
'download_content_length' => -1,
'upload_content_length' => 0,
'starttransfer_time' => 0.344,
'redirect_time' => 0,
'certinfo' => array(),
); |
$curl_info = curl_getinfo($ch);$curl_info = array( 'url' => 'https://tosiek.pl/', 'content_type' => 'text/html; charset=utf-8', 'http_code' => 200, 'header_size' => 862, 'request_size' => 52, 'filetime' => -1, 'ssl_verify_result' => 0, 'redirect_count' => 0, 'total_time' => 0.344, 'namelookup_time' => 0.047, 'connect_time' => 0.172, 'pretransfer_time' => 0.172, 'size_upload' => 0, 'size_download' => 80, 'speed_download' => 232, 'speed_upload' => 0, 'download_content_length' => -1, 'upload_content_length' => 0, 'starttransfer_time' => 0.344, 'redirect_time' => 0, 'certinfo' => array(),); |
| curl_errno | Zwraca numer ostatniego błędu lub 0 (zero) w przypadku braku błędów. | $curl_error_number = curl_errno($ch); |
$curl_error_number = curl_errno($ch); |
| curl_error | Zwraca opis i wiadomość dotyczącą ostatniego błędu. W celu upewnienia się, że błąd wystąpił użyj funkcji curl_errno, która zwraca 0 (zero) jeśli wszystko jest w porządku a po napotkaniu błędu, jego numer lub curl_exec z kolei ta zwraca FALSE przy błędzie. | $curl_error_message = curl_error($ch); |
$curl_error_message = curl_error($ch); |
| curl_copy_handle | Kopiuje parametry danej sesji i zwraca w postaci nowego uchywtu sesji. | $ch2 = curl_copy_handle($ch); |
$ch2 = curl_copy_handle($ch); |
| curl_close | Zamyka pojedynczą sesję cURL i zwalnia użyte zasoby (pamięć etc.). Usuwa takze uchwyt cURL $ch. | |
| curl_multi_init | Inicjuje multi-sesję i zwraca uchwyt dla niej, nie przyjmuje żadnych argumentów. | |
| curl_multi_add_handle | Dodaje zwykłą pojedynczą sesję cURL do jednej multi-sesji którą trzeba uprzednio utworzyć. | curl_multi_add_handle($mh, $ch); |
curl_multi_add_handle($mh, $ch); |
| curl_multi_exec | Wywołuje i aktywuje multi-sesje, pierwszy parametr uchwyt multi-sesji stworzony za pomocą curl_multi_init a drugi informacja o tym czy jest aktywna ta multi-sesja. | $mrc = curl_multi_exec($mh, $active);
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
while ($active && $mrc == CURLM_OK) {
if (curl_multi_select($mh) != -1) {
do {
$mrc = curl_multi_exec($mh, $active);
} while ($mrc == CURLM_CALL_MULTI_PERFORM);
}
} |
$mrc = curl_multi_exec($mh, $active);do { $mrc = curl_multi_exec($mh, $active);} while ($mrc == CURLM_CALL_MULTI_PERFORM);while ($active && $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); }} |
| curl_multi_select | Czeka aż wszystkie dane zostaną zwrócone przy wszystkich połączeniach multi-sesji lub aż upłynie czas timeout; zwraca -1 przy błędach. Przyjmuje dwa parametry, uchwyt multi-sesji oraz czas timeout. | $ready = curl_multi_select($mh, '15.0'); |
$ready = curl_multi_select($mh, '15.0'); |
| curl_multi_info_read | Zwraca informacje o multi-sesji w tablicy z trzema kluczami; “msg” zwraca zawsze: ‘CURLMSG_DONE’, “result” zwraca jeden wynik spośród: ‘CURLE_*’; w przypadku powodzenia zwraca: ‘CURLE_OK’, “handle” zwraca uchwyt sesji cURL, której to informacje dotyczą. Powtórne wywołanie funkcji zwróci kolejne inne wyniki. Przyjmuje dwie wartości, pierwsza to uchwyt multi-sesji a druga to zmienna przechowująca ilość wiadomości w kolejce. | $curl_multi_info = curl_multi_info_read($mh);
$curl_multi_info = array(
'msg' => CURLMSG_DONE,
'result' => CURLE_OK,
'handle' => resource(2, curl),
); |
$curl_multi_info = curl_multi_info_read($mh); $curl_multi_info = array( 'msg' => CURLMSG_DONE, 'result' => CURLE_OK, 'handle' => resource(2, curl),); |
| curl_multi_getcontent | Jeżeli “CURLOPT_RETURNTRANSFER” jest ustawione na TRUE to zwraca zawartość strony, jedyny argument to zwykła sesja pojedynczego – uchwyt cURL. | $content = curl_multi_getcontent($ch); |
$content = curl_multi_getcontent($ch); |
| curl_multi_remove_handle | Usuwa sesję pojedynczego cURL z multi-sesji i umożliwia wykonanie curl_exec na zwolnionym uchwycie, po tym należy zamknąć multi-sesję oraz pojedyncze sesje żeby zwolnić użyte zasoby. | curl_multi_remove_handle($mh, $ch1); |
curl_multi_remove_handle($mh, $ch1); |
| curl_multi_close | Kończy multi-sesję, nadal jednak należy usunąć zwykłe sesje z multi-sesji za pomocą curl_multi_remove_handle oraz zakończyć każdą zwykłą pojedynczą sesje cURL aby zwolnić zasoby. | |
| curl_version | Zwraca informacje o cURL w postaci tablicy. | $version = curl_version(); |
$version = curl_version(); |




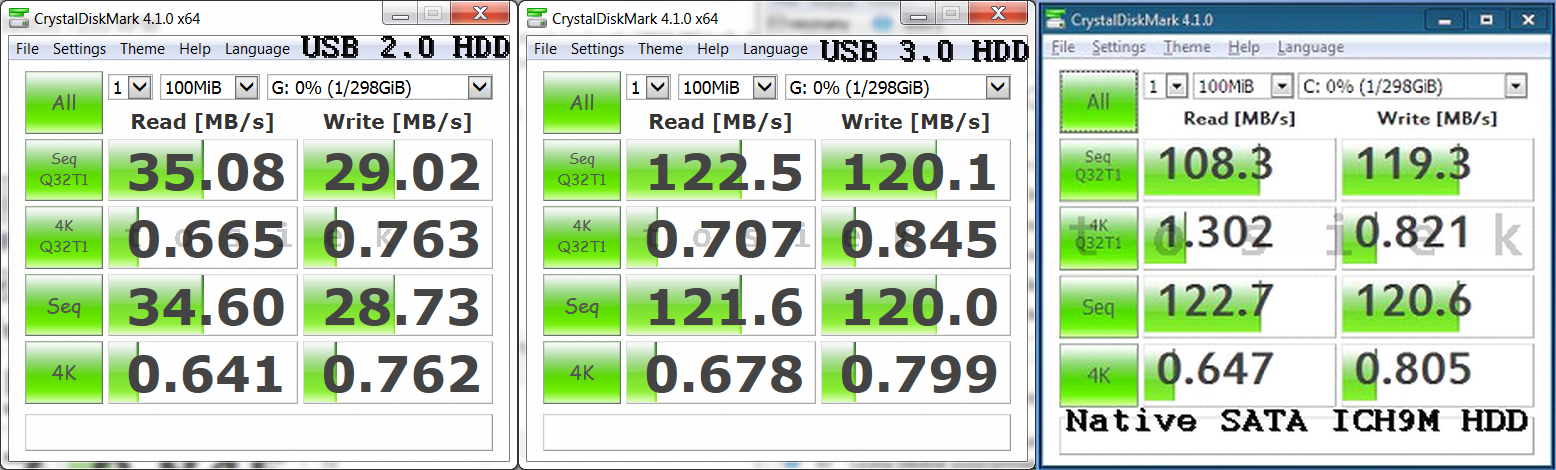


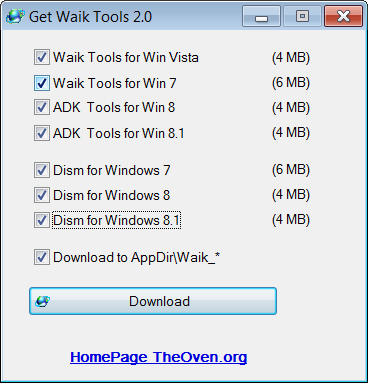
 . (cały czas musimy pamiętać o architekturze x64 lub x86)
. (cały czas musimy pamiętać o architekturze x64 lub x86)



Najnowsze komentarze